
I can help you conduct data analysis and reporting using Matlab
- 0
- (0)

Project Details
Why Hire Me?
📱Click to Connect on Whatsapp to Discuss Your Project
With over 7 years of experience across industries and academia, I specialize in MATLAB-based data analysis and reporting that turns technical datasets into clear, actionable insights. My services are ideal for engineering, scientific, and research-driven projects.
Key Strengths:
-
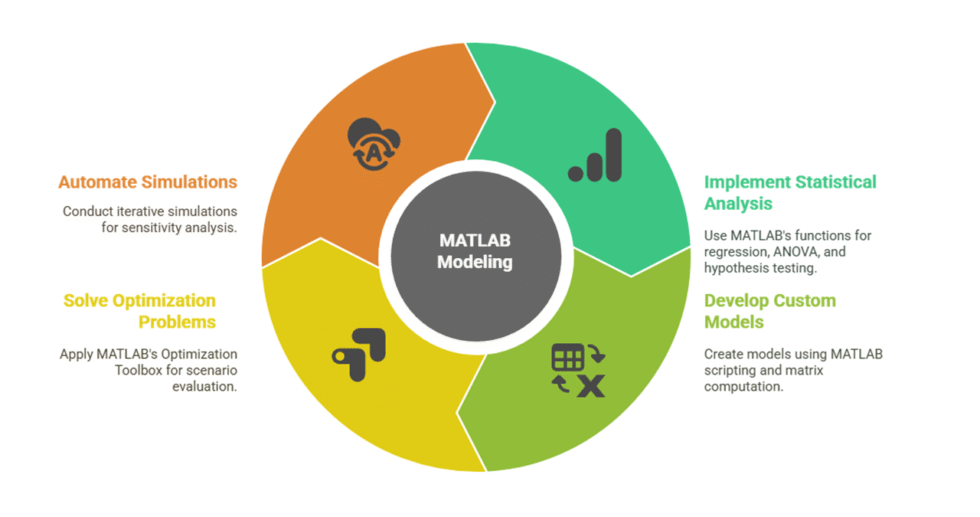
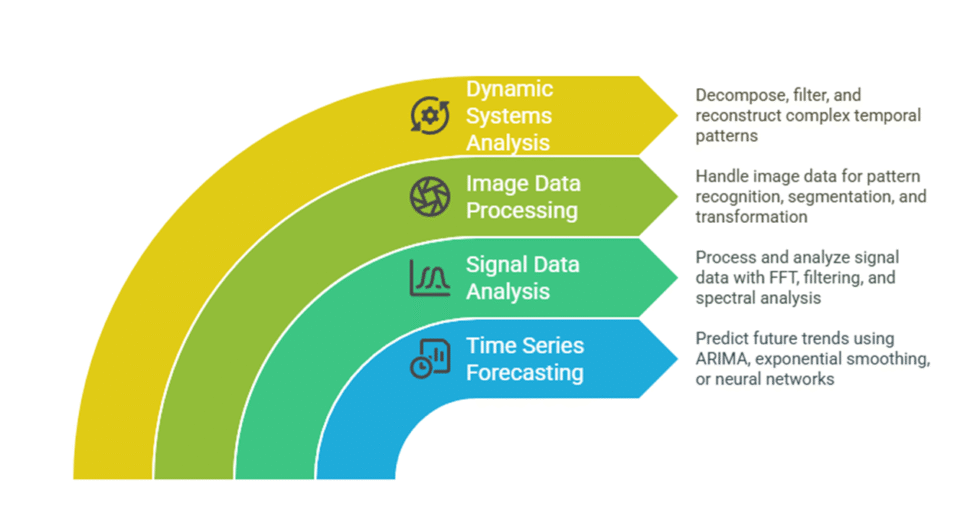
Advanced expertise in signal processing, simulations, modeling, and statistical analysis
-
Skilled in MATLAB toolboxes like Optimization, ML, and Time Series
-
Strong background in preprocessing, scripting, and structured reporting
-
Deliverables suitable for both academic and professional audiences
-
Clear communication, sector adaptability, and emphasis on reliability
What I Need to Start Your Work
To provide precise, efficient service, kindly share the following:
1) Project Scope and Objectives
-
Clear summary of what the analysis is intended to achieve
-
Any hypotheses, research questions, or KPIs being evaluated
2) Data Details
-
File format, size, source, and brief about the dataset
-
Specific variables to focus on or exclude
-
Notes on any preprocessing already performed
3) MATLAB Requirements
-
Analysis functions/toolboxes expected (e.g., Curve Fitting, Simulink, ML Toolbox)
-
Any required custom scripts or models
-
If applicable, upload sample MATLAB files
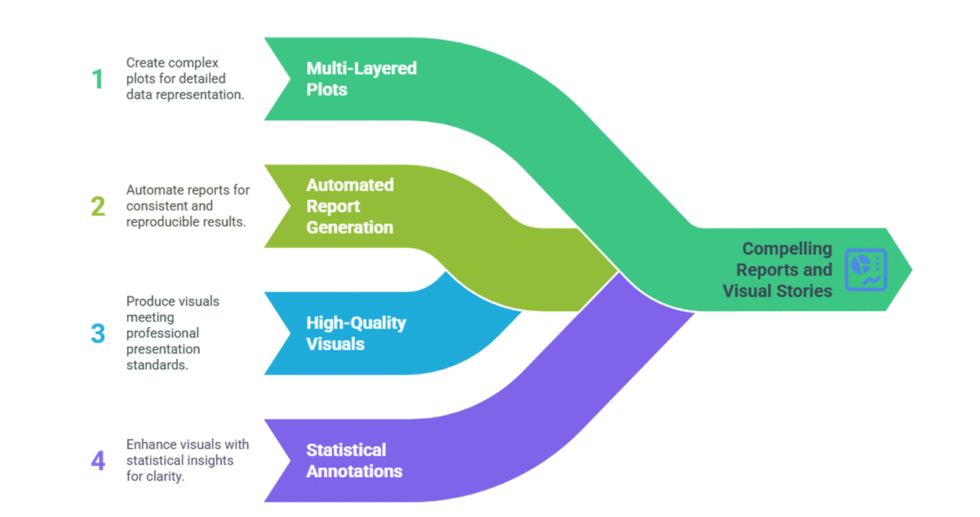
4) Reporting Requirements
-
Desired format (PDF, Word, PPT, or LaTeX)
-
Sections required (e.g., Introduction, Methods, Results, Discussion)
-
Data visualization preferences (charts, plots, diagrams)
5) Ethics and Privacy
-
Guidelines on data sensitivity or non-disclosure expectations
-
Specific compliance standards (if institutional or organizational)
6) Timeline
-
Deadline for project delivery
-
Suggested intervals for draft submission or check-ins
7) Communication Preferences
-
Preferred platform (Email, WhatsApp, Google Docs)
-
Expectations for progress updates and file sharing
8) Additional Notes
-
Prior examples to follow (if any)
-
Any preferred modeling approach or output format
Portfolio
Power Consumption Outlier Detection in MATLAB
Developed an anomaly detection system in MATLAB to identify irregular energy usage patterns from smart meter data. Enabled proactive response to potential grid faults and customer misuse.
CLV Prediction Using MATLAB Time Series Models
Used MATLAB to forecast Customer Lifetime Value (CLV) using behavioral and transaction data. Combined statistical modeling with business logic to support targeted retention strategies.
MATLAB-Based Trend Analysis on Education Data
Used MATLAB to identify performance trends in national academic assessments across regions and subjects. Delivered statistical findings and data-driven recommendations for policymakers and curriculum planners.
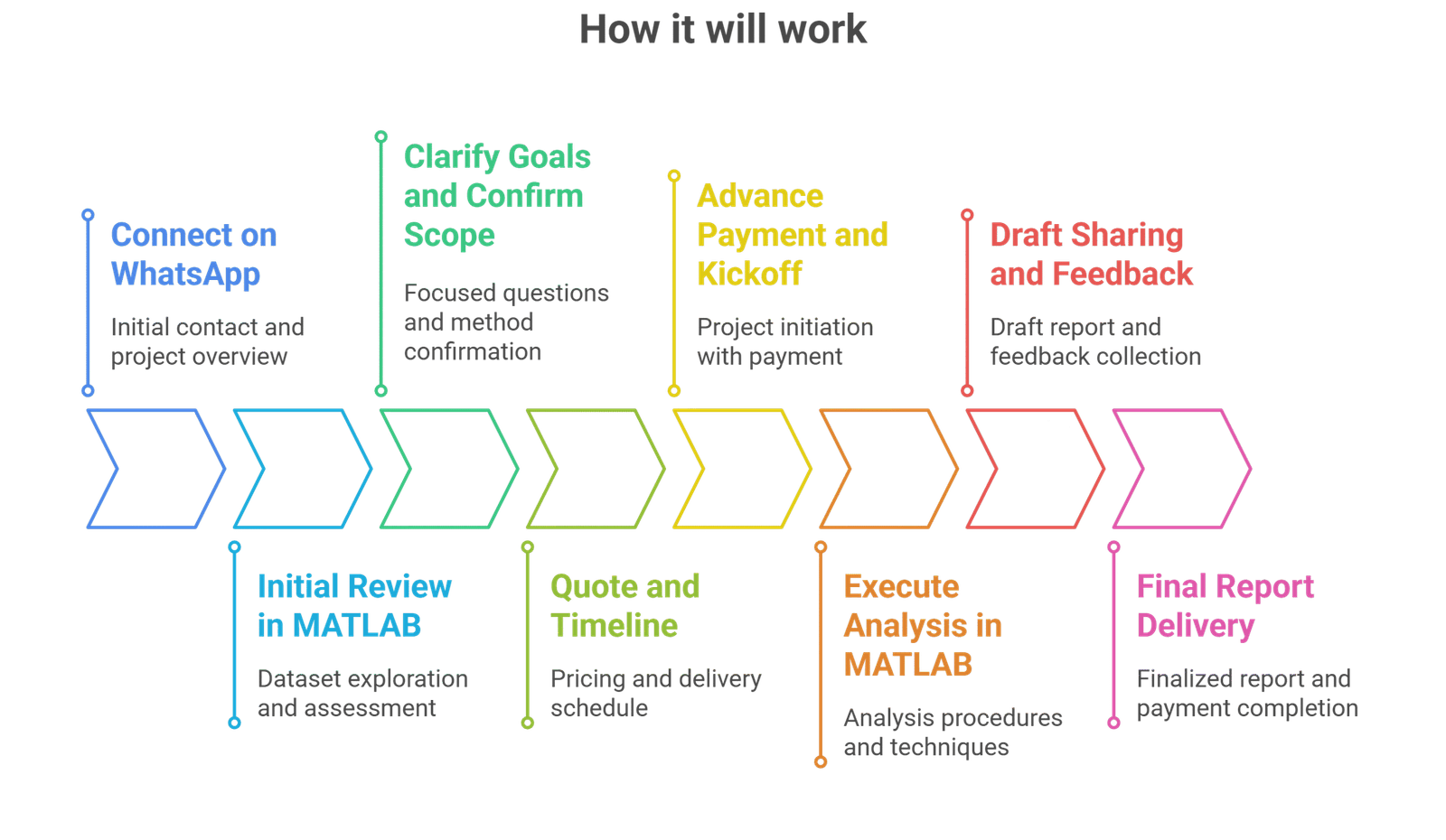
Process
MATLAB Quick Analysis
Starts at $55
Entry-level statistical analysis
-
 3
Days Delivery
3
Days Delivery
-
 1
Revision
1
Revision
MATLAB Core Reporting
Starts at $95
Statistical models with interpretations
-
5
Days Delivery
-
3
Revisions
MATLAB Expert Insights
Starts at $150
Full-stack data analysis + reporting
-
8
Days Delivery
-
Unlimited
Revisions






